Redis
Redis
一、使用场景
1、缓存穿透
查询一个不存在的数据,mysql查询不到数据也不会直接写入缓存,导致每次请求都会查询数据库
1.1 解决方法
缓存空数据,查询返回的数据为空,仍把这个数据缓存
1.1 缺点:消耗内存,可能会发生不一致的问题
布隆过滤器

主要是通过数组来判断的,但是会出现误判
2.1 缺点: 实现复杂,存在误判
2、缓存击穿
当给某个key设置了过期时间,当key过期的时候,恰好这个时间点对这个key有大量的并发请求过来,这些并发的请求可能会瞬间把数据库压垮
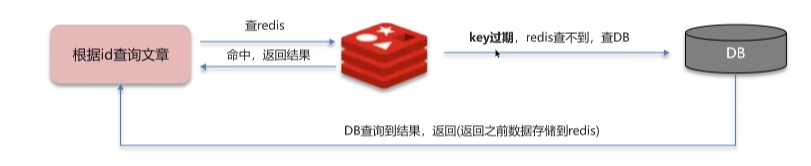
2.1 解决方法
互斥锁
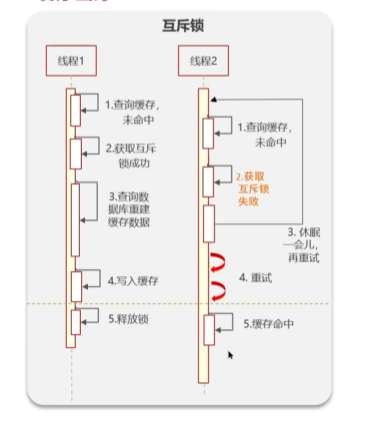
强一致,性能差
逻辑过期
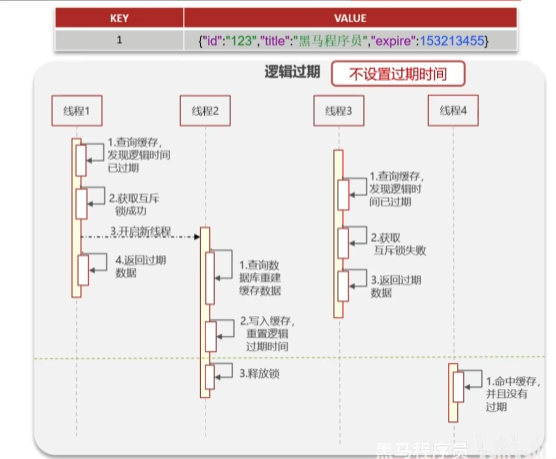
高可用,性能优,不能保证数据的绝对一致
3 缓存雪崩
指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量的请求到达数据库,带来巨大的压力
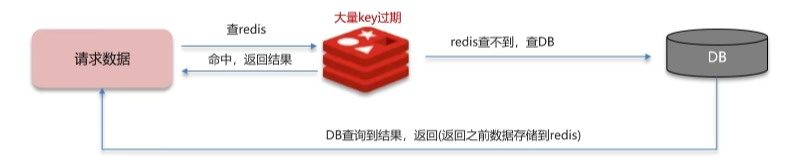
3.1 解决方法
- 给不同的key的TTL添加随机值
- 利用Redis集群提高服务的可用性 如:哨兵模式,集群模式
- 给缓存业务添加降级限流策略 如:nigix或者springcloud gateway
- 给业务添加多级缓存
4 redis作为缓存,mysql的数据如何与redis进行同步?(双写一致性)
4.1 双写一致性
当修改了数据库中的数据也要同时更新缓存中的数据,缓存中的数据要和数据库中的数据保存一致

读操作:缓存命中,直接返回;缓存未命中查询数据库,然后写入缓存,设置超时时间
写操作:延迟双删

应该是先删除缓存还是先删除数据库?
先删除缓存,在操作数据库
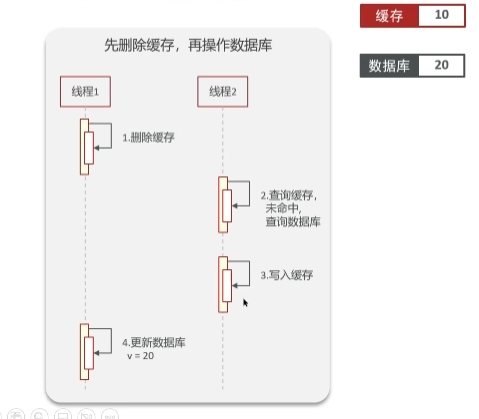
会出现脏数据的现象
先操作数据库,在删除缓存
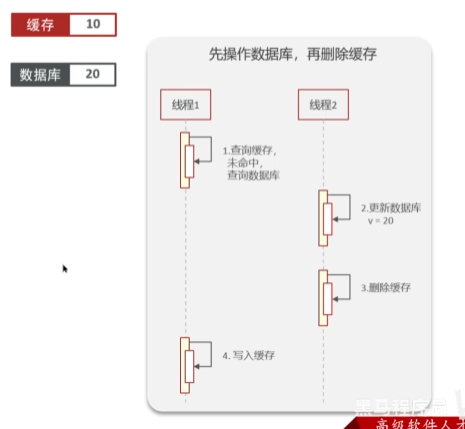
也会出现问题
可以使用分布式锁实现
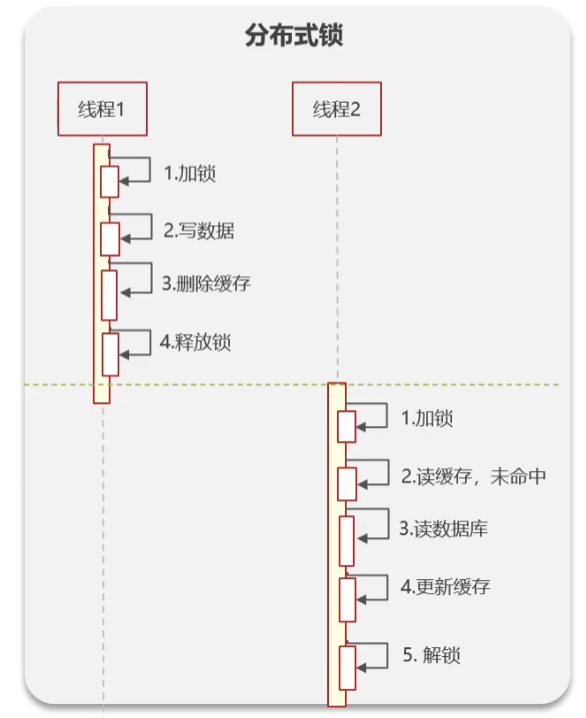
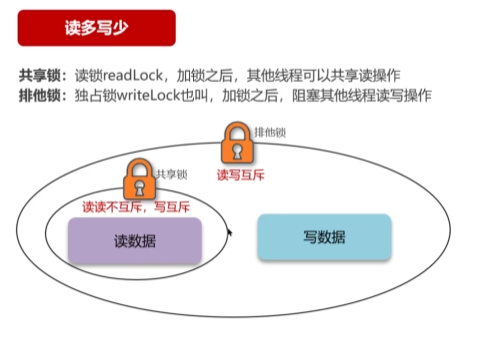
最好的方式
使用mq实现
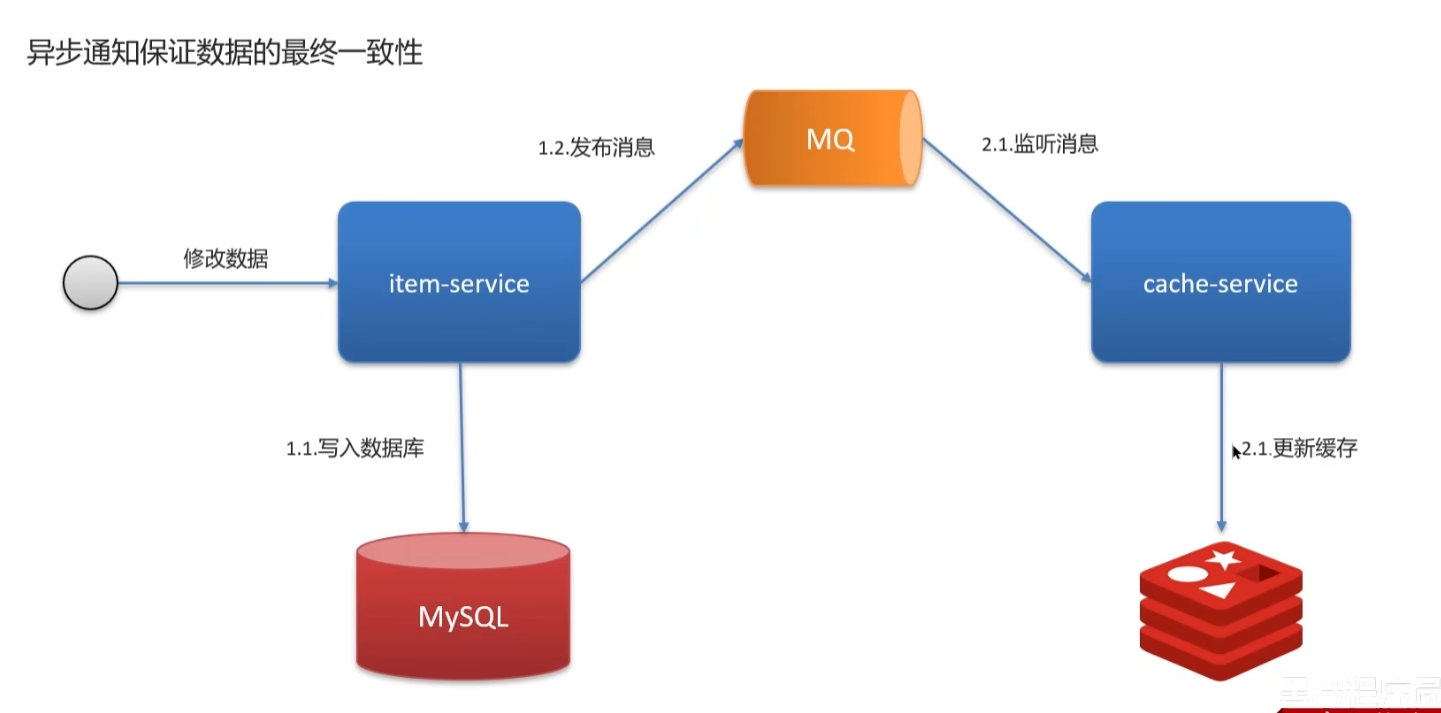
5 redis 作为缓存,数据的持久化是怎么做的?
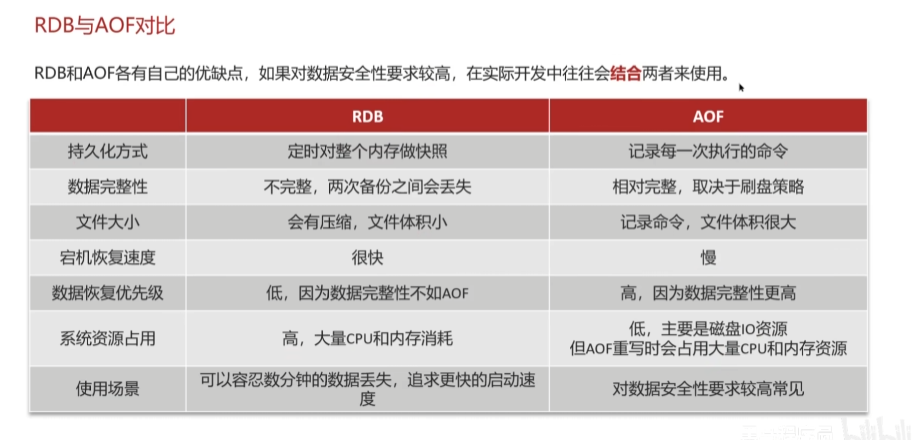
5.1 RDB
RDB 全称 Redis Database Backup file ( Redis 数据备份文件),也被叫做 Redis 数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。当 Redis 实例故障重启后,从磁盘读取快照文件,恢复数据
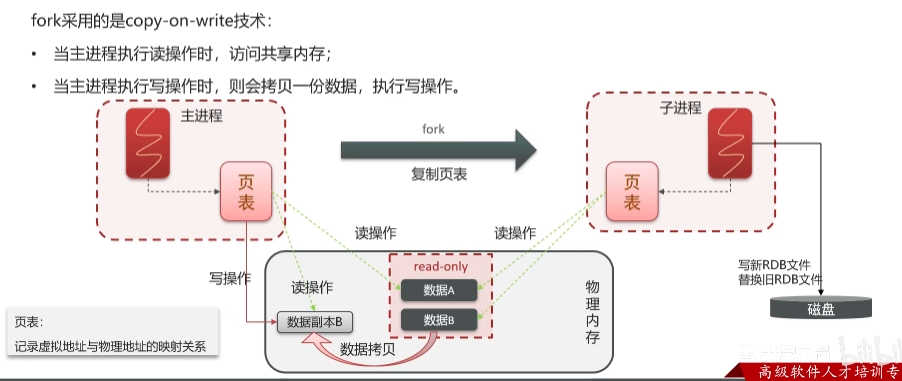
5.1.1 RDB的执行原理
bgsave开始时会fork主进程得到子进程,子进程共享主进程的内存数据,完成fork后读取内存数据并写入RGB文件。
5.2 AOF

6 假如redis的key过期后,会立即删除吗?
6.1 惰性删除
置该key过期时间后,我们不需要去管他,当需要该key时,我们再检查其是否过期,如果过期,我们就删除,反之返回该key
6.2 定期删除
每隔一段时间,我们就对key进行检查,删除里面过期的key(从一定数量的数据库中取出一定数量的随机key进行检查,并删除其中的过期key)
两种模式:
- Slow模式是定时任务,执行频率默认为 10hz ,每次不超过 25ms ,以通过修改配置文件 redis.conf 的 hz 选项来调整这个次数
- FAST 模式执行频率不固定,但两次间隔不低于 2ms ,每次耗时不超过 1ms
7 假如缓存过多,内存是有限的,内存被占满了怎么办?(数据淘汰策略)
数据的淘汰策略:当 Redis 中的内存不够用时,此时在向 Redis 中添加新的 key ,那么 Redis 就会按照某一种规则将内存中的数据删除掉,这种数据的删除规则被称之为内存的淘汰策略。
Redis支持8种不同的策略来选择要删除的key:
- noeviction : 不淘汰任何 key ,但是内存满时不允许写入新数据,默认就是这种策略
- volatile-ttl : 对设置了 TTL 的 key ,比较 key 的剩余 TTL 值, TTL 越小越先被淘汰
- allkeys-random :对全体 key ,随机进行淘汰。
- volatile-random :对设置了 TTL 的 key ,随机进行淘汰。
- allkeys-lru : 对全体 key ,基于 LRU 算法进行淘汰。LRU 最近最少使用,LFU:最少频率使用
- volatile-lru : 对设置了 TTL 的 key ,基于 LRU 算法进行淘汰
- allkeys-lfu : 对全体 key ,基于 LFU 算法进行淘汰
- volatile-lfu : 对设置了 TTL 的 key ,基于 LFU 算法进行淘汰
使用策略
- 优先使用 allkeys-lru 策略。充分利用 LRU 算法的优势,把最近最常访问的数据留在缓存中。如果业务有明显的冷热数据区分,建议使用。
- 如果业务中数据访问频率差别不大,没有明显冷热数据区分,建议使用allkeys-random ,随机选择淘汰。
- 如果业务中有置顶的需求,可以使用 volatile-lru 策略,同时置顶数据不设置过期时间,这些数据就一直不被删除,会淘汰其他设置过期时间的数据。
- 如果业务中有短时高频访问的数据,可以使用 allkeys-lfu 或 volatile-lfu 策略。

8 redis 分布式锁,是如何实现的?(场景:集群情况下的定时任务,抢单,幂等性)
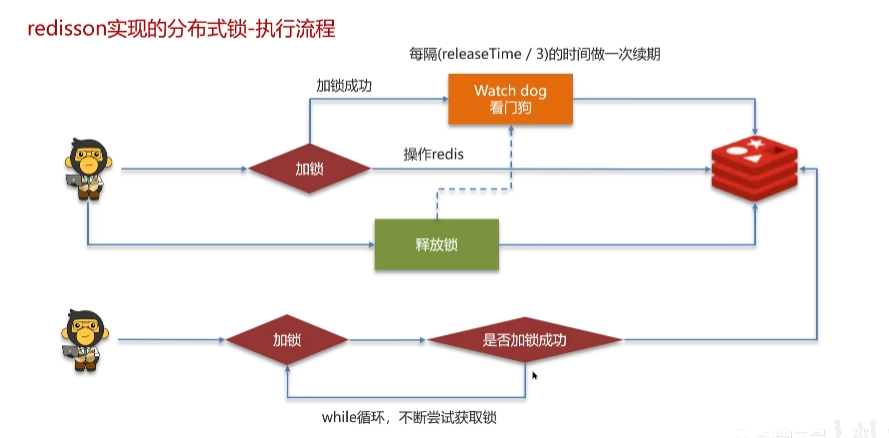
redisson实现的分布式锁可重入
主从一致性
使用红锁:不能只在一个redis实例上创建锁,应该在多个redis实例上进行创建锁
9 Redis集群有哪些方案?
在redis中提供的集群方案总共有三种
- 主从复制
- 哨兵模式
- 分片集群
9.1 主从复制


9.2 哨兵模式
redis提供了哨兵机制来实现主从集群的自动故障恢复,主要作用:
监控:哨兵会不断检查master和slave是否按预期工作
自动故障恢复:如果master故障,哨兵会将一个slave提升为master。当故障实例恢复后也以新的master为主
通知:哨兵充当redis客户端的服务发现来源,当集群发生故障转移时,会将最新的信息推送给redis客户端
哨兵选主的规则
- 首先判断主与从节点断开时间长短,如超过指定值就排该从节点
- 然后判断从节点的 slave-priority 值,越小优先级越高
- 如果 slave-prority 一样,则判断 slave 节点的 offset 值,越大优先级越高
- 最后是判断 slave 节点的运行 id 大小,越小优先级越高。
redis集群(哨兵模式)脑裂
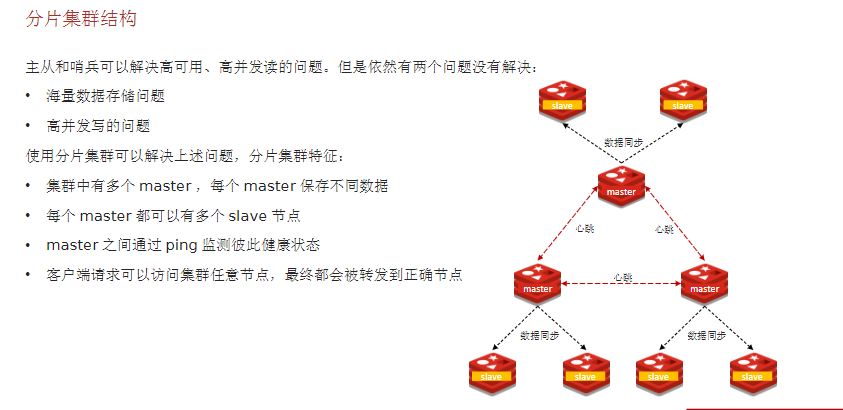
9.3 分片集群结构
10 其他问题

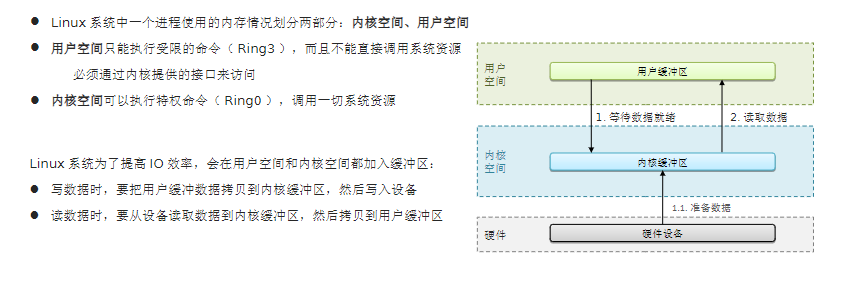
10.1 用户空间和内核空间
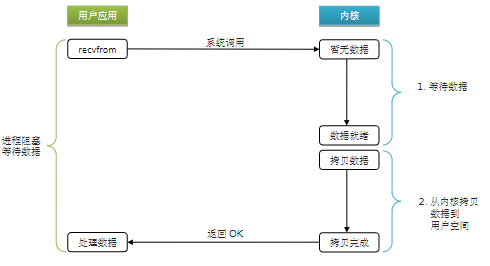
10.2 阻塞IO
阶段一:
- 用户进程尝试读取数据(比如网卡数据)
- 此时数据尚未到达,内核需要等待数据
- 此时用户进程也处于阻塞状态
阶段二:
- 数据到达并拷贝到内核缓冲去,代表已就绪
- 将内核数据拷贝到用户缓冲区
- 拷贝过程中,用户进程依然阻塞等待
- 拷贝完成,用户进程接触阻塞,处理数据
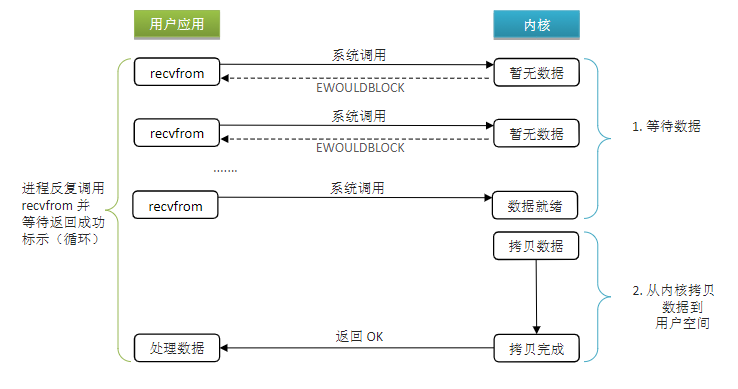
10.3 非阻塞IO
阶段一:
- 用户进程尝试读取数据(比如网卡数据)
- 此时数据尚未到达,内核需要等待数据
- 返回异常给用户
- 用户进程拿到error后,再次尝试读取
- 循环往复,知道数据就绪
阶段二:
- 将内核数据拷贝到用户缓冲区
- 拷贝过程中,用户进程依然阻塞等待
- 拷贝完成,用户进程接触阻塞,处理数据
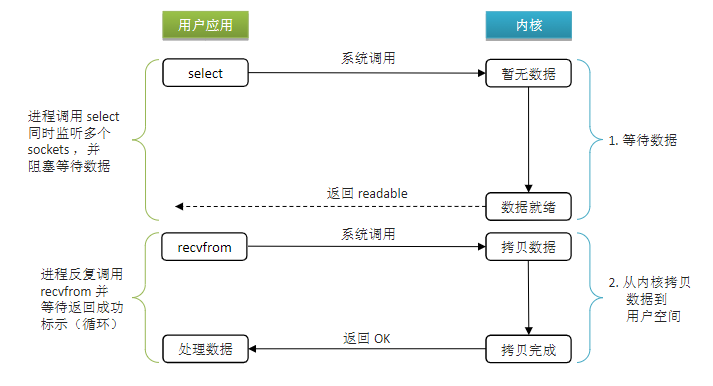
10.4 IO多路复用
IO多路复用:是利用单个线程来同时监听多个 Socket ,并在某个 Socket 可读、可写时得到通知,从而避免无效的等待,充分利用 CPU 资源。
阶段一:
- 用户进程调用 select ,指定要监听的 Socket 集合
- 内核监听对应的多个 socket
- 任意一个或多个 socket 数据就绪则返回 readable
- 此过程中用户进程阻塞
阶段二:
- 用户进程找到就绪的 socket
- 依次调用 recvfrom 读取数据
- 内核将数据拷贝到用户空间
- 用户进程处理数据
End SpringBoot整合Redis
1、 配置类
@EnableCaching
@Configuration
public class RedisConfig extends CachingConfigurerSupport {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
RedisSerializer<String> redisSerializer = new StringRedisSerializer();
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
template.setConnectionFactory(factory);
//key序列化方式
template.setKeySerializer(redisSerializer);
//value序列化
template.setValueSerializer(jackson2JsonRedisSerializer);
//value hashmap序列化
template.setHashValueSerializer(jackson2JsonRedisSerializer);
return template;
}
@Bean
public CacheManager cacheManager(RedisConnectionFactory factory) {
RedisSerializer<String> redisSerializer = new StringRedisSerializer();
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
//解决查询缓存转换异常的问题
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
// 配置序列化(解决乱码的问题),过期时间600秒
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofSeconds(600))
.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(redisSerializer))
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(jackson2JsonRedisSerializer))
.disableCachingNullValues();
RedisCacheManager cacheManager = RedisCacheManager.builder(factory)
.cacheDefaults(config)
.build();
return cacheManager;
}
}
2、springboot 缓存注解说明
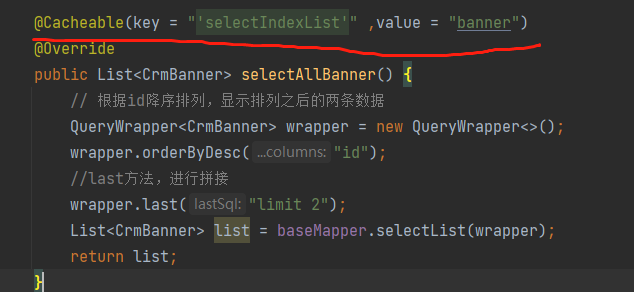
2.1 缓存@Cacheable
根据方法对其返回结果进行缓存,下次请求时,如果缓存存在,则直接读取缓存数据返回;如果缓存不 存在,则执行方法,并把返回的结果存入缓存中。一般用在查询方法上。
| 属性/方法名 | 解释 |
|---|---|
| value | 缓存名,必填,它指定了你的缓存存放在哪块命名空间 |
| cacheNames | 与 value 差不多,二选一即可 |
| key | 可选属性,可以使用 SpEL 标签自定义缓存的key |
2.2 缓存@CachePut
使用该注解标志的方法,每次都会执行,并将结果存入指定的缓存中。其他方法可以直接从响应的缓存 中读取缓存数据,而不需要再去查询数据库。一般用在新增方法上。
| 属性/方法名 | 解释 |
|---|---|
| value | 缓存名,必填,它指定了你的缓存存放在哪块命名空间 |
| cacheNames | 与 value 差不多,二选一即可 |
| key | 可选属性,可以使用 SpEL 标签自定义缓存的key |
2.3 缓存@CacheEvict
使用该注解标志的方法,会清空指定的缓存。一般用在更新或者删除方法上
| 属性/方法名 | 解释 |
|---|---|
| value | 缓存名,必填,它指定了你的缓存存放在哪块命名空间 |
| cacheNames | 与 value 差不多,二选一即可 |
| key | 可选属性,可以使用 SpEL 标签自定义缓存的key |
| allEntries | 是否清空所有缓存,默认为 false。如果指定为 true,则方法调用 后将立即清空所有的缓存 |
| beforeInvo cation | 是否在方法执行前就清空,默认为 false。如果指定为 true,则在 方法执行前就会清空缓存 |
3 使用过程
在需要存储数据的方法上面添加@Cacheable注解,注解里面写入需要添加的key和value